22.10.20 – Unternehmensübergreifende Kooperation dank Datenanalyse
DigiTextil-Projekt: Business Intelligence
Eigene Unternehmensgrenzen überwinden, denn eine ganzheitliche Betrachtung der gesamten Wertschöpfungskette birgt enormes wirtschaftliches Potential.
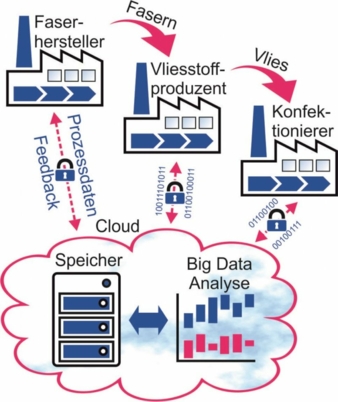
Prinzipskizze des DigiTextil-Projekts © ITA/RWTH
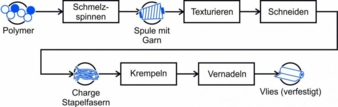
Übersicht der Prozessschritte sowie der Zwischenprodukte, die die Unternehmensgrenzen verlassen. © ITA/RWTH
Die Digitalisierung schreitet in der deutschen Industrie immer weiter voran. Auch Entscheidungsträger in der von kleinen und mittelständischen Unternehmen dominierten Textilindustrie haben längst den Nutzen der Digitalisierung erkannt. Es werden neue Geschäftsmodelle und Prozesse entwickelt, die auf digitalen Technologien basieren. Dabei sind die eigenen Unternehmensgrenzen häufig die Grenzen des Betrachtungsrahmens, obwohl eine ganzheitliche Betrachtung der gesamten Wertschöpfungskette enormes wirtschaftliches Potential birgt. Gründe für die Einschränkungen sind vor allem die Furcht vor Datenverlust und Offenlegung von Know-how. Diese Probleme behandelt das DigiTextil-Projekt.
DigiTextil-Projekt: Problemstellung
Die Produktion von Textilien erfolgt in stark fragmentierten Prozessketten. So stellen Unternehmen Zwischenprodukte her, die von anderen Unternehmen weiterverarbeitet werden. Ein vollständiger, unternehmensübergreifender Informationsfluss zu den eingesetzten Produkten und Prozessparametern findet dabei nicht statt. Aufgrund von Stillständen und Ausschuss – auch durch fehlerhafte Vorprodukte ausgelöst – entsteht in der KMU dominierten deutschen Vliesstoffproduktion ein wirtschaftlicher Schaden in Höhe von ca. 366 Mio. Euro pro Jahr. Laut Studien von McKinsey können solche Ausfälle durch gezielte Speicherung und Analyse von Big Data in der Produktion um bis zu 20 Prozent reduziert werden. Schon bei einer Reduktion von 5 Prozent entspricht die Einsparung einem Betrag von 80.000 Euro pro Jahr und KMU.
Die zentrale Analyse von Produktionsdaten entlang der gesamten Prozesskette ist wegen des hohen Einsparpotentials prinzipiell sinnvoll. In der Praxis wird dieses Prinzip jedoch nicht angewendet, was vor allem auf zwei Gründe zurückzuführen ist:
- Verlust von Know-how und Rezepturen durch Weitergabe der Daten wird befürchtet.
- Zulieferer fürchten den sogenannten Blaming-Effekt. Kommt es zu Reklamationen, wird die Schuld häufig bei den verwendeten Rohstoffen des Zulieferers gesucht.
- Dieses Prinzip schmälert die Bereitschaft des Zulieferers, Daten zu teilen.
Das Projekt DigiTextil
Im Rahmen des DigiTextil-Projekts widmet sich das Institut für Textiltechnik der RWTH Aachen University (ITA) und das FIR e. V. der RWTH Aachen University dem beschriebenen Problem. Die untersuchte Ziel-Leistungskennzahl ist der Ausschuss in der Produktion. Das Projekt wird aus einem Konsortium aus Vertretern der IT-Branche, Anlagenbauern und Produzenten sowie Kanzleien, die sich auf Datenrecht spezialisiert haben, beraten und unterstützt.
Die zentrale untersuchte Frage lautet:
„Wie kann eine von allen Unternehmen freiwillig genutzte und unternehmensübergreifende Vernetzung entlang der Prozesskette realisiert werden?“
Als prinzipieller Ansatz wurde eine zentrale Cloud als Datentreuhändler gewählt. Alle teilnehmenden Unternehmen übertragen ausgewählte Produktionsdaten in Echtzeit dorthin. In der Cloud findet eine Big-Data-Analyse der Daten statt, deren Ergebnisse den Unternehmen mitgeteilt werden. Ein zentraler Erfolgsfaktor ist das Prinzip der Freiwilligkeit: Die Ergebnisse der Analyse werden nur übermittelt, wenn alle betreffenden Unternehmen zustimmen. So behalten die Unternehmen die Datenhoheit. Ein weiterer wichtiger Erfolgsfaktor ist die Datensicherheit. Alle Daten werden prinzipiell verschlüsselt übertragen. Des Weiteren sorgen hohe Vertragsstrafen bei Datenmissbrauch dafür, dass Datensicherheit die oberste Priorität des Datentreuhändlers ist.
Die am ITA errichtete Infrastruktur und konkret umgesetzte Geschäftsmodelle
Am ITA wurde ein Beispielprozess realisiert, an dem die entwickelte Methodik angewendet und validiert werden kann. Der gewählte Prozess ist die Produktion eines Nadelvlieses, da dieser mehrere Zwischenprodukte mit mehreren beteiligten Unternehmen umfasst.
Der Betrachtungsrahmen beginnt mit dem Polymer, was im Schmelzspinnprozess zum Garn ausgesponnen wird. Das gesponnene Garn wird an ein Unternehmen geliefert, welches das Garn konfektioniert. Die durchgeführten Schritte sind das Texturieren und die anschließende Verarbeitung zu Stapelfasern. Die so produzierten Stapelfasern werden bei einem Vliesstoffproduzenten gekrempelt. Das Krempelvlies wird danach vernadelt, sodass am Ende ein verfestigter Vliesstoff vorliegt. Bei jedem Prozessschritt werden alle verfügbaren Prozessdaten erfasst und in eine zentrale Datenbank geschrieben, die die Cloud repräsentiert. Das Sammeln der Prozessdaten basiert auf der Annahme, dass in den Daten Hinweise auf Prozessfehler verborgen sind. Die Prozessfehler führen zu Ausschuss in späteren Verarbeitungsschritten. Der generierte Datensatz kann dazu verwendet werden, nach Ursachen für den Ausschuss zu suchen oder den Ausschuss sogar präventiv zu vermeiden. Beispiele für erfasste, qualitätsrelevante Prozessgrößen beim Spinnen sind die Temperatur der Schmelze oder die Menge der verwendeten Avivage zur Oberflächenbehandlung des Garns.
Des Weiteren werden alle Zwischenprodukte im Labor des ITA analysiert. Auf diese Weise wird ein zusätzlicher Datensatz für die Qualität der Zwischenprodukte generiert, mit dem die Ursachen für bestimmte Fehler identifiziert werden können. Am Beispiel des Garns werden unter anderem die Feinheit, Zugfestigkeit und Bruchdehnung bestimmt.
Geschäftsmodelle basierend auf Datenanalyse
Geschäftsmodelle, die auf Datenanalyse basieren, werden dem Bereich der Business Intelligence zugeordnet. Diese ermöglichen neuartige Ansätze, mit denen die Einsparungen beim Ausschuss erzielt werden können. Die Geschäftsmodelle basieren alle auf den gesammelten Datensätzen und werden den Kunden des Cloud-Anbieters als einzelne Services angeboten. Alle Teilnehmer des Netzwerks, darunter verschiedene Zulieferer und Produzenten, benutzen den Cloud-Dienst als Plattform. Diese Plattform muss für jeden Teilnehmer Anreize schaffen, Daten zu teilen, indem ein Nutzen für alle generiert wird. Der Verlust von Know-how sowie der Blaming-Effekt müssen unter allen Umständen vermieden werden. Im Folgenden werden drei zentrale Geschäftsmodelle präsentiert, die durch die cloudbasierte Datensammlung und -analyse ermöglicht werden.
- Fehlerursachenanalyse: Bei der Qualitätssicherung werden Produktfehler schnell identifiziert. Die Ursachenanalyse dagegen ist aufwendiger, wenn sie überhaupt stattfindet. Da die Prozessdaten in der Cloud vorliegen, kann in dem Datensatz nach Ursachen für die identifizierten Fehler gesucht werden. Mittels Machine Learning werden Modelle trainiert, die verborgene Zusammenhänge in den Daten erkennen. Die Analyse der Modelle liefert die Ursache des Fehlers, sodass dieser in Zukunft vermieden werden kann. Nach der Zustimmung aller Dateneigentümer werden die Analyseergebnisse präsentiert. Bei diesem Geschäftsmodell werden konkrete Probleme und konkrete Ursachen diskutiert, sodass Maßnahmen im Vordergrund stehen und der Blaming-Effekt minimiert wird. Der offensichtliche Vorteil für Produzenten ist, dass Ausschuss langfristig verringert wird. Der Zulieferer erhält Informationen, wie er seine Prozesse kundenspezifisch verbessern kann, um ihn an sich zu binden. Insgesamt werden Zusammenarbeit und Kommunikation entlang der Lieferkette gefördert. Die Problematik besteht vor allem darin, dass zunächst nur wenige Daten für das Modelltraining zur Verfügung stehen.
- Prädiktive Vermeidung von Ausschuss: Die im vorherigen Geschäftsmodell trainierten Modelle können auch dazu verwendet werden, prädiktiv Ausschuss zu vermeiden. Wenn die Ursachen bekannt sind, können diese in Echtzeit direkt am Prozess erkannt werden, ohne dass das fehlerhafte Produkt überhaupt ausgeliefert wird. Der Zulieferer vermeidet dadurch Reklamationen und der Produzent vermeidet Ausschuss. Der Cloud-Betreiber übernimmt bei diesem Geschäftsmodell teilweise die Aufgaben der Qualitätssicherung. Der Vorteil liegt auch hier in der Verwendung von Machine Learning, was Zusammenhänge in großen Datensätzen erkennen kann, die Menschen unter Umständen nicht entdecken. Über Machine Learning werden dadurch Zusammenhänge aufgedeckt, die im Betrieb eventuell nie hinterfragt worden sind.
- Zertifizierung von Produkten: Das dritte Geschäftsmodell ist die Auszeichnung von Produkten mit einem individuellen Zertifikat. Über die Erfassung der Prozessdaten liegen zahlreiche digitale Informationen über ein bestimmtes Produkt vor. Man spricht auch von einem digitalen Schatten des Produkts. Die generierten Modelle zur Prädiktion von Qualitätsfehlern werden in einer virtuellen Qualitätskontrolle auf den digitalen Schatten angewendet. Eventuelle Fehler können so erkannt werden. Wird kein Fehler detektiert, dann wird ein Zertifikat erstellt, dass das Produkt erfolgreich geprüft worden ist. Das Zertifikat kann individuell auf den späteren Verwendungszweck angepasst werden. Ein Beispiel ist ein Vliesstoff, dem besonders gute optische Eigenschaften bescheinigt werden. Ein Zulieferer kann seinen Produkten auf diese Weise einen Mehrwert geben. Einem Produzenten wird durch das Zertifikat eine Hilfestellung bei der Auswahl des Rohstoffes gegeben. Die Schwierigkeit bei diesem Geschäftsmodell liegt darin, dass die Daten- und Modellqualität sehr hoch sein müssen, um Fehlerfreiheit mit ausreichender Sicherheit garantieren zu können.
Systemarchitektur
- Um die beschriebenen Geschäftsmodelle umsetzen zu können, muss eine leistungsfähige Systemarchitektur vorliegen.
- Eine Systemarchitektur definiert das Zusammenspiel der einzelnen Komponenten des Cloud-Dienstes.
- Als Basis der Architektur wurde das DIN-genormte Referenzarchitekturmodell Industrie 4.0 (RAMI 4.0) gewählt, das den Cloud-Dienst auf mehrere Schichten mit steigendem Abstraktionsgrad ordnet.
Als Basis dient der Asset-Layer, der die physischen Prozesse und Produkte enthält. Dort werden auch die Prozesszustände mittels Sensoren erfasst. Der Communication Layer behandelt danach die verschlüsselte Übertragung der Daten in die Cloud. Der Information Layer hat die Aufgabe, aus den aufgezeichneten Daten Informationen zu generieren. Diese Informationen werden zum Schluss im Functional Layer anwendungsbezogen verarbeitet, etwa zur Fehlerursachenidentifikation.
Besondere Aufmerksamkeit wird im Projekt dem Information Layer gewidmet.
Um zu ermitteln, welche Informationen vorliegen müssen, wurde analysiert, was einen realen Produktionsprozess definiert. Nach [DIN14] werden Prozesse durch Ströme (Stoffe, Energie und Informationen), die die Prozessgrenzen überschreiten, sowie die internen Zustände beschrieben. Die internen Zustände sowie Energieströme (z. B. der Stromverbrauch) müssen so vollständig wie möglich durch Sensoren erfasst werden.
Ein prädiktives Modell kann daher maximal so gut sein wie die Qualität der vorliegenden Daten.
Die wichtigsten Stoffe, die die Prozessgrenzen überschreiten, sind die verwendeten Rohstoffe sowie das Produkt des Prozesses. Das Produkt des einen Prozessschrittes ist der Rohstoff des nächsten. Da Fehler an Produkten identifiziert werden sollen, wird der gesamte Lebenszyklus jedes Zwischenproduktes in seinem digitalen Schatten erfasst. Der digitale Schatten verweist auf die aufgezeichneten Prozessdaten während der Produktion sowie den Rohstoff, aus dem das Produkt hergestellt wurde. So entsteht eine Kette, in der alle verfügbaren Informationen abrufbar sind. Dieses Schema ist besonders flexibel, da es die Erfassung der Qualität direkt am Prozess oder auch nachträglich am fertigen Produkt im Labor oder der Qualitätssicherung erlaubt. Eine Grundvoraussetzung ist, dass jedes Zwischenprodukt maschinenlesbar identifizierbar ist, etwa durch QR- oder RFID-Tags. Die Herausforderung des gewählten Datenmodells ist es, die verschiedenen industriellen Prozesstypen (Batch, Stück, kontinuierliche Fahrweise) sauber abzubilden, weshalb jeder digitale Schatten eine individuell auf den Prozess zugeschnittene Struktur aufweisen muss.
Im Functional Layer werden die oben beschriebenen Informationen anwendungsbezogen verarbeitet. Hier befinden sich die eigentlichen Anwendungen bzw. Services, die bereits im Rahmen der Geschäftsmodelle diskutiert worden sind. Die gewählte Serviceorientierte Architektur (SOA) erlaubt das flexible Hinzufügen individueller Cloud-Anwendungen, um die aufgezeichneten Daten optimal ausnutzen zu können.
Fazit und Ausblick
Das DigiTextil-Projekt soll unternehmensübergreifende Zusammenarbeit fördern, indem für alle Teilnehmer einer Plattform ein Nutzen auf freiwilliger Basis generiert wird. Dem Schutz der Daten gilt dabei die oberste Priorität. Konkret wird der Nutzen dadurch generiert, dass mittels Machine Learning Fehler in Prozessen identifiziert werden. So können Reklamationen und Ausschuss minimiert werden.
In aktuellen Arbeiten werden die Methoden zur Datenanalyse in der Cloud am FIR und am ITA entwickelt und getestet. Die ersten Ergebnisse dieser Arbeiten werden zeitnah erwartet. Prinzipiell hat das Projekt aufgrund des großen Einsparpotentials eine hohe Relevanz für die Wirtschaft. Die zentrale Herausforderung für die Anwendbarkeit in der Praxis liegt in der Skalierung des Prinzips vom Labormaßstab auf die heterogen ausgeprägte industrielle Prozesslandschaft. Für jeden realen Produktionsprozess muss zunächst ein individuelles Schema entwickelt werden.
Ruben Kins, Frederik Cloppenburg, Jan Thiel, Justus Benning, Thomas Gries
[DIN14] DIN SPEC Deutsches Institut für Normung 40912 (2014). Kernmodelle – Beschreibung und Beispiele